
Когда не хватает таргетинга по данным Метрики, геолокации, CRM системы или пикселя Аудиторий, на помощь приходит сегменты похожих (look alike) пользователей.
Look alike аудитории в Яндексе – это сегменты пользователей, частично или максимально похожих на посетителей вашего сайта по интересам и поведению в сети.
Работает это так. Есть сегмент Аудиторий на основе любых данных. Создаете сегмент похожей аудитории и система идет собирать данные. При этом она опирается на те характерные особенности, которые присущи начальной выборке.
Например, выделили женщин 25-35 лет, побывавших на сайте в течение последних 30 дней и посетивших категорию кэжуал одежды. Забросили эту информацию в сервис и далее он по набору идентификаторов (а на самом деле по личным данным Яндекс.Паспорта, кэшу, времени и длительности посещения и пр.) состряпает базу дам бальзаковского возраста, которые интересуются одеждой на сайтах интернет-магазинов.
Интересный инструмент, однако не всегда эффективный. Но обо всем по порядку.
Look alike аудитории как настроить
2 варианта создания.
- Жмем три точки ••• справа, появляется контекстное меню:

- или: желтая кнопка «Создать сегмент» → «Похожий сегмент»:
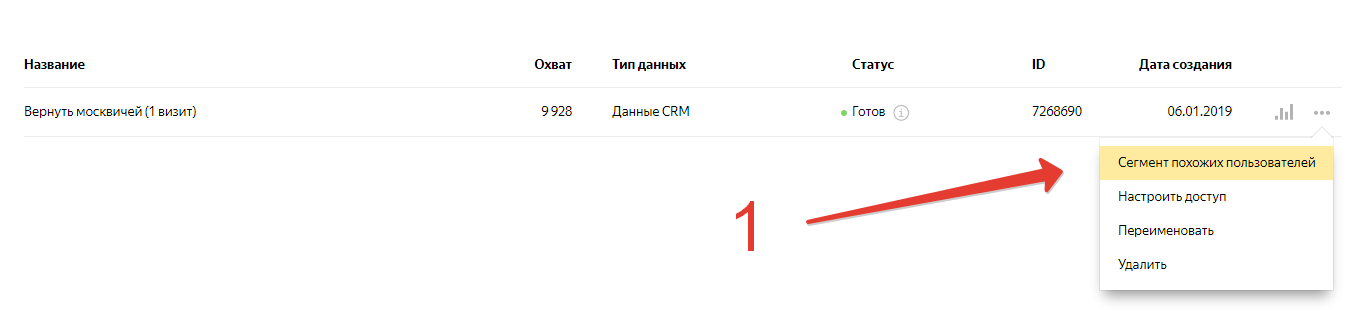
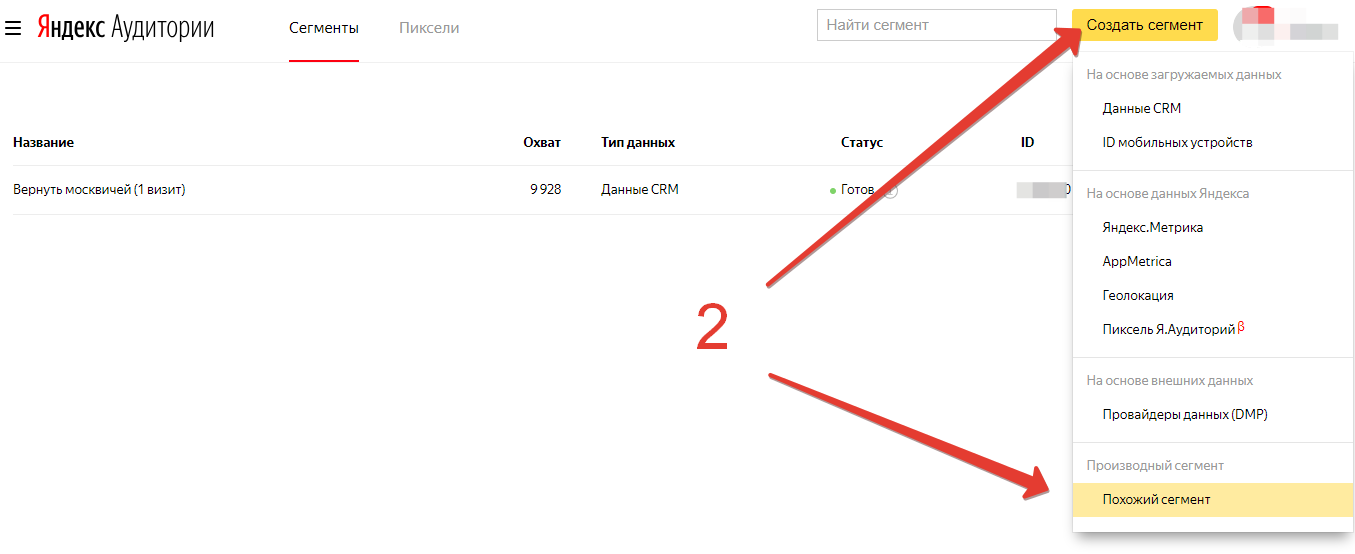
В обоих случаях дальше появляется такое окно:
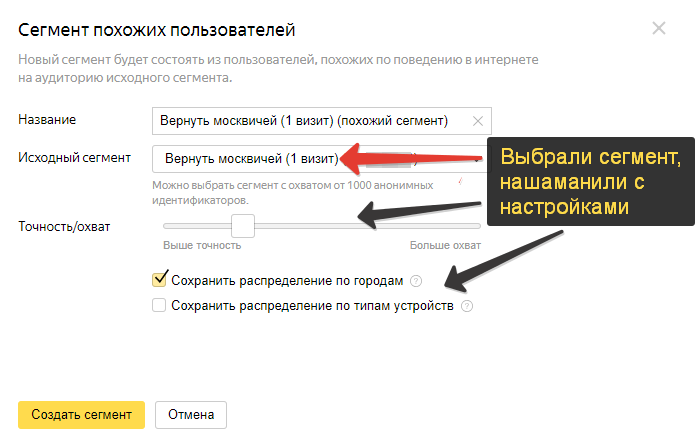
Вбиваете название, выбираете исходник для обработки и далее идет интересная настройка: ползунок точности/охвата. С помощью него можно определиться, что для вас важнее.
Учитывайте, что большой охват имеет широкое соответствие параметрам. Иными словами, система выделяет какие-то крупные поведенческие признаки (женщины, 25-35 лет), а остальные отсеивает в угоду количеству. В итоге мы слабо понимаем, кого насобирали → высокий риск слива бюджета в ретаргетинге.
И наоборот, высокая точность даст более чистый результат. Однако слишком жесткие или специфичные рамки исходного сегмента могут просто не собрать нужный охват (не менее 1000 идентификаторов). То же самое с целым рядом узких ниш – не соберешь 1000 контактов под фотопечать на дереве в Анадыри.
Далее. Ниже есть настройки по городам и типам устройств – с помощью галочек можно указать системе, хотим ли мы применить эти фильтры при поиске похожей публики.
Тут собака порылась – если сервис не сможет собрать свой минимум по городам или устройствам, то он АВТОМАТИЧЕСКИ добавит аудитории без учета данных настроек.
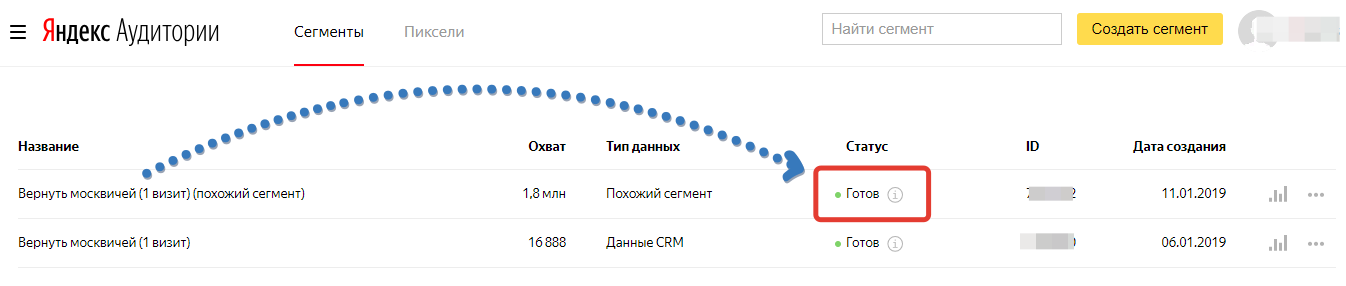
Как только нужный охват соберется, видим стандартную надпись:
Как использовать в Директе
Идем в параметры группы объявлений → Ретаргетинг и подбор аудитории:
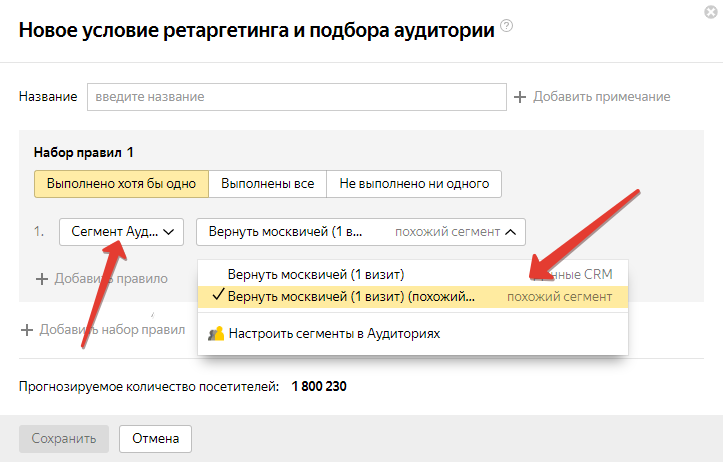
Выбираем похожий сегмент и задираем на него ставку.
Второй вариант – создаем наборы правил. Как это работает и как сделать, я рассказывал в статье про сегменты Метрики в Аудиториях, почитайте концовку с примерами.
Варианты применения
В каких случаях нужен look-alike?
- Увеличить охват, про это я уже писал в начале. Ретаргетинг вялый, хочется больше обратной связи.
- Имиджевая реклама. Хотим показать продукт большему количеству пользователей, при этом не сильно распыляясь на общую массу.
- Экономия бюджета. Есть ниши с супердорогим поиском, где вся надежда на РСЯ и ретаргетинг. Тут похожие аудитории могут сильно пригодиться.
Минусы инструмента
- Если собираете данные под бОльший охват – есть вариант потратить деньги на нецелевую публику.
- Если собираете данные по определенным географии или устройствам и этих данных не хватает, система автоматом соберет все города и устройства. Худо придется владельцам местных кафешек, у которых посетители ребята с айфонами.
Как-то так. Комментируем, я это люблю ))









Отправляя сообщение, Вы разрешаете сбор и обработку персональных данных.
Соглашение о сборе, обработке и хранении персональных данных.